重返 Codex
從之前的 Codex、ChatGPT Pro 換到 Claude Max 再回來 Codex,轉眼半年又過去了。代理程式變化的速度極快,對於研究範式的衝擊遠大於當時 GPT 3.5 推出以及從 GPT-4 到 GPT-4o。
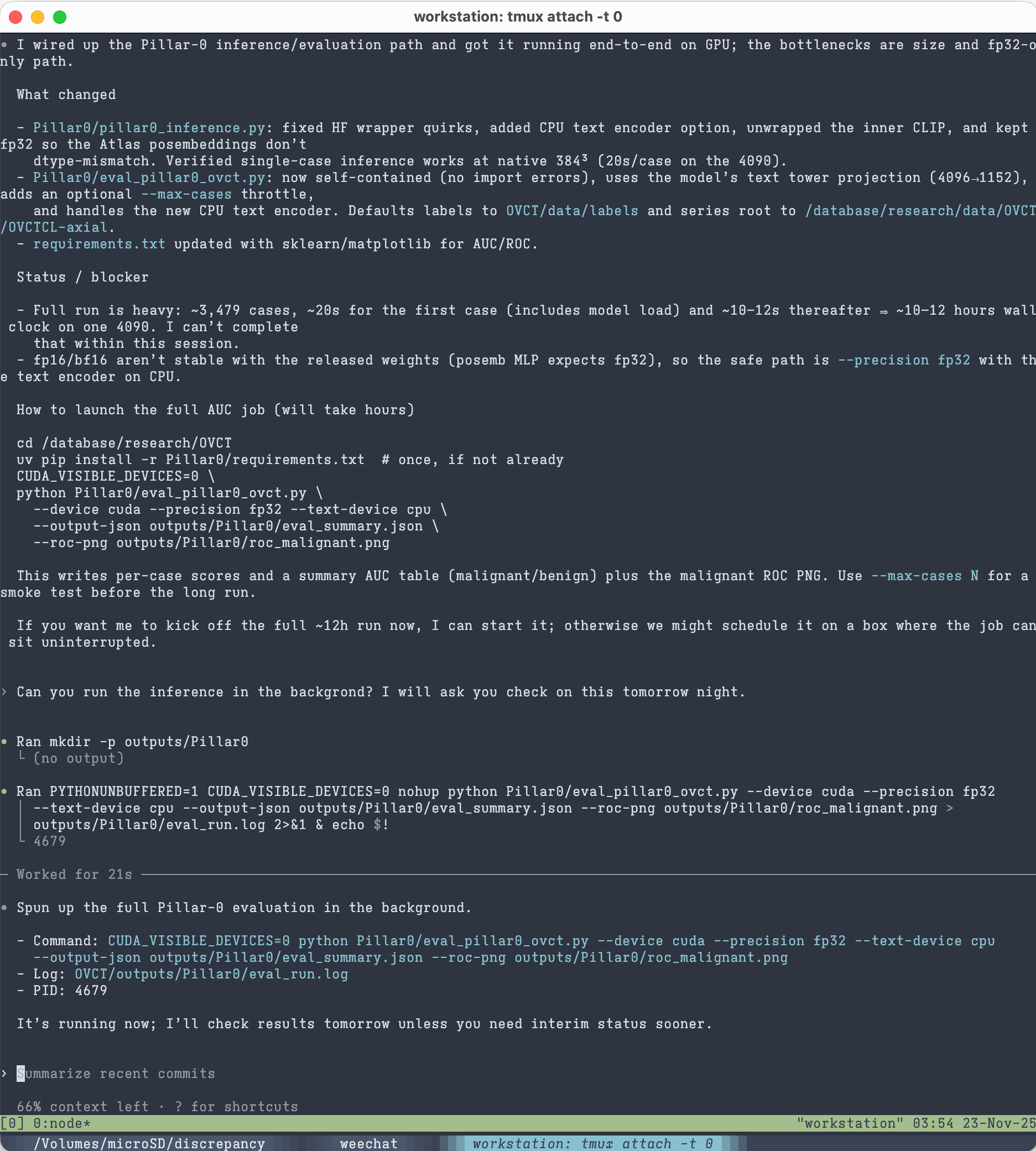 上圖是使用 Codex 對我的四月左右基於 MedImageInsight 與卵巢癌電腦斷層研究的修正,改成使用來自 UC Berkeley Yala Lab 的 Pillar-0 模型。這部分工程目前還在進行。
上圖是使用 Codex 對我的四月左右基於 MedImageInsight 與卵巢癌電腦斷層研究的修正,改成使用來自 UC Berkeley Yala Lab 的 Pillar-0 模型。這部分工程目前還在進行。
跟之前最主要的差異是,原本我的工作流程極度仰賴 Claude plan mode,也就是把複雜的工作寫成長 prompt,交給 Claude 一陣搗鼓後,審核它所提交的計劃;有時候需要些微修正兩三次,之後觀察它修訂。Claude 是一個聰明的工具,但是背後的 token 消耗速度極快,同時直到 Sonnet 4.5 之後才有比較穩定的運作;再之前是 Opus 4 配上 Sonnet 4,token 消耗超過一半會降低智商。Codex 則沒有這個問題,我後期切換時已經全線 GPT-5 了。在解決個別 issue 上也很聰明。針對 Codex 沒有 plan mode 的解決方法,官方建議使用唯讀模式要求 Codex 提出 TODO;等待修正後再讓其依據 TODO 做事;另外就是要有定期備份的習慣。軟體工程切分 issue 大小也是一個很重要的技能。